
What is Retrieval Augmented Generation? A Visual Guide On RAGs in the Context of LLMs
Without Fine-tuning, Integrate Custom Information and External Data Sources To Give LLMs Relevant Context To Hallucinate Less And Be More Accurate

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
Consider sharing this with someone who wants to know more about machine learning.

New here and don’t know where to begin?
Read the Getting Started page to find your way around The Code Compass.
In the rapidly evolving field of artificial intelligence, large language models (LLMs) such as ChatGPT-4, Gemini, Claude, and LLAMA have become household names.
Making an LLM perform well on your custom use case can be a costly affair. Pre-training ChatGPT-4 required 10s of TB of data, 100M$, and 100s of cutting-edge GPUs.

You could always fine-tune a pre-trained model on your data using LoRA to reduce the number of parameters tuned to less than 1% of total model parameters!
But what if you do not have access to a high-quality fine-tuning dataset and compute? RAG for LLMs or retrieval augmented generation can help you solve your problem.
Without the need to re-train or fine-tune, Retrieval Augmented Generation (RAG), elevates the capabilities of LLMs by integrating them with external knowledge sources such as databases, file systems, or knowledge graphs. This article goes over (the technicalities of) RAG and why you should care about it.
Would like to read other related pieces?
Here you can read more about the Transformers series and LLMs series.
1. The Rise of Retrieval Augmented Generation
RAG emerged as a solution to one of the fundamental challenges faced by LLMs: their dependence on static, pre-existing knowledge. While these models are trained on vast amounts of data, their knowledge is limited to what was available during their training phase.
If you have used ChatGPT or other LLMs, you might have noticed a cut-off date i.e. the model is pre-trained on “internet data” until that date. So if you would like to query information on recent events and the model does not know about them, you might not get the response you seek.
This is where RAG steps in, enabling models to access and retrieve information from external sources, thus enhancing their ability to provide “more” accurate and up-to-date responses.
!["Attention, Please!": A Visual Guide To The Attention Mechanism [Transformers Series]](https://substackcdn.com/image/fetch/$s_!mFbk!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F375dc525-fa19-4e6f-81f2-68820bfd36a1_1903x856.png)
2. Why Should You Care About RAG: Overcoming the limitations of LLMs
RAG addresses several limitations of LLMs:
Integrate Sources of Information to Generate Responses
LLMs, despite their impressive capabilities, are limited to the knowledge they were trained on. RAG allows these models to access external databases, documents, and APIs, integrating up-to-date information into their responses. This integration ensures that the responses are not only accurate but also rich in context and detail.
External sources of information provide the LLM more relevant context. This context helps the LLM respond correctly to incoming queries.
Imagine trying to integrate an LLM to answer questions from attendants in a medical setting such as a hospital. The LLM does not have knowledge or any data about your patients, health records, procedures, etc.

Remedy Out-of-Date Pre-Trained Models
One significant challenge with pre-trained models is that they can become outdated quickly as new information emerges. RAG mitigates this issue by allowing the model to retrieve the latest data during its operation. This capability is particularly valuable in fields where information is constantly evolving, such as technology, medicine, and current events.
Model Grounding and Trustworthy LLM Responses
RAG enhances the grounding of models, ensuring that the generated content is anchored in verifiable and relevant data. This grounding improves the trustworthiness and reliability of the model's outputs, as the information is drawn from credible and up-to-date sources.
Enhanced Contextual Understanding
By retrieving external information, RAG improves the model's understanding of the context, enabling it to generate more relevant and nuanced responses. This contextual enhancement is crucial for complex queries that require detailed and specific knowledge.
Enhancing Accuracy and Relevance
By leveraging external data sources, RAG significantly improves the accuracy and relevance of the generated content. For instance, if a user asks about the latest research in quantum computing, a RAG-based system can retrieve the most recent papers and integrate their findings into the response. This not only ensures the information is current but also enhances the depth and quality of the generated text.



3. An Intuitive Explanation of RAG: Closed-Book vs. Open-Book
RAG can be viewed as a hybrid system that brings together the strengths of retrieval-based models and generative models.
Imagine you are preparing for an important exam. There are two different exam formats you could face: an open-book exam, where you can bring and refer to your textbooks, and a closed-book exam, where you rely solely on what you have memorized.
RAG is like the open-book exam where you have access to the relevant context when responding to questions in the exam.
The Closed-Book Approach: Traditional LLMs
Traditional large language models (LLMs) operate like students taking a closed-book exam. These models are trained on vast amounts of data, learning patterns, facts, and language structures during their training phase. When they generate text, they rely solely on this internalized knowledge. This method allows for fast and fluent text generation, but it has some limitations:
Outdated Information: The knowledge base of the model is fixed at the time of training. Any information emerging after this period is not available to the model.
Knowledge Gaps: No matter how extensive the training data is, there will always be gaps in the information that the model has internalized.
Static Understanding: The model cannot adapt to new information or changes in the real world.
The Open-Book Approach: RAG
On the other hand, the retrieval mechanism in RAG functions like a student in an open-book exam. When faced with a question, the student can look up the latest information in textbooks or online resources, ensuring their answer is accurate and up-to-date. This approach has its own strengths:
Up-to-date Information: By accessing external sources, the model can provide information that reflects the most current knowledge.
Comprehensive Coverage: It can retrieve specific details from vast databases, filling in gaps that the closed-book memory might have.
Domain-Specific Context: External sources can include niche and domain-specific information. It is likely that the model has not seen such type of information at all during pre-training or fine-tuning. But with RAG, it is able to generate relevant responses thanks to the relevant context.
4. The Mechanics of RAG
To understand RAG, it’s essential to break down its components and how they work together:
Retrieval Mechanism
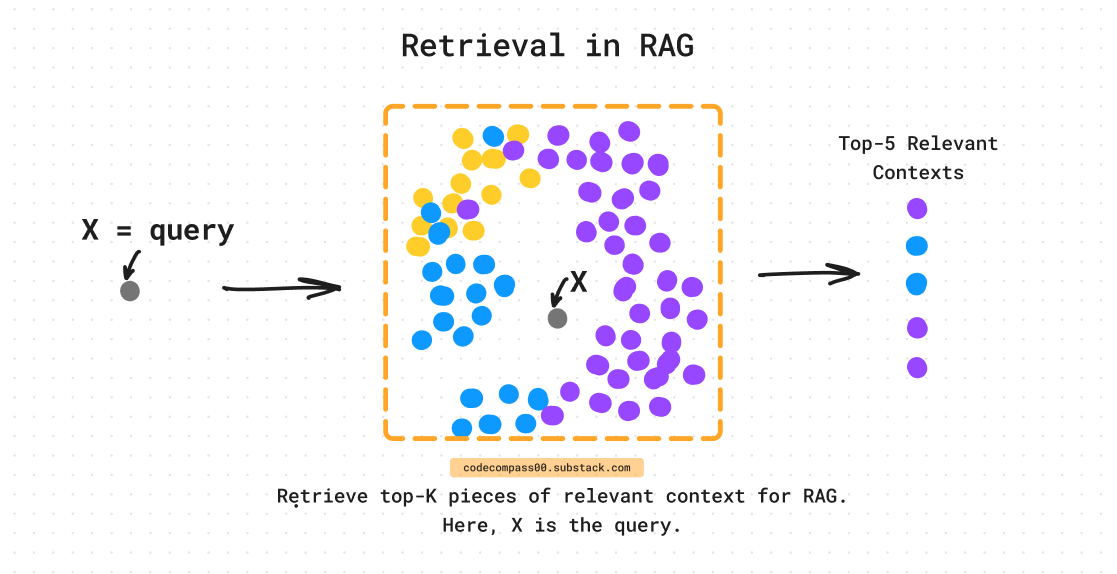
The retrieval component is responsible for accessing external knowledge sources. When a query is received, this mechanism searches relevant databases, documents, or APIs to find the most pertinent information. The retrieved data is then fed into the generation mechanism.
Retrieving relevant information is key. Big tech companies like Apple and Netflix have used embeddings to solve similar problems in their products. They use embeddings.

If you don’t have time to read how they use it, here is a gist:
This is usually done via embeddings of (1) the external information sources and (2) the incoming query to the LLM. The similarity between the query embeddings and external information embeddings is computed. The most similar hits are passed on to the LLMs as relevant context.
This can be implemented using vector DBs such as Chroma, Pinecone, Qdrant, or other popular vector DBs.

If you are not a fan of embeddings you could use any other mechanism that is able to fetch the “relevant context”. For example, one could be a little more “exotic” and send the query to a search engine, fetch the top 3 web pages from the search, and send it to the LLM as “relevant context”.
Generation Mechanism
The generation mechanism, typically an LLM, takes the retrieved information and incorporates it into the generated text. This process involves aligning the retrieved data with the query context to produce coherent and contextually appropriate responses.
The LLM generates text “keeping in mind” the context that was the output of the retrieval mechanism. The fact that this context is most relevant to the query made to the LLM, we hope that it contains critical information to answer the query correctly.
Putting Together Retrieval and Generation
Finally, with the retrieval and generation mechanisms ready to go, we need an integration glue to put them together and behave as an end-to-end pipeline that ingests queries to the LLMs and outputs the LLMs response.
Of course, inside the end-to-end pipeline, we have the retrieval of relevant context and augmenting the LLMs response generation.

5. The Future of RAG
RAG represents a significant leap forward in the capabilities of LLMs, enabling them to provide more accurate, relevant, and timely information. As AI continues to advance, RAG will likely become a standard component in the architecture of next-generation models, enhancing their ability to interact with and leverage vast external knowledge sources.
Expanding Use Cases
With the integration of RAG, the scope of applications for LLMs expands significantly. Fields such as healthcare, finance, and law can benefit from more precise and updated information retrieval, leading to better decision-making and outcomes.
Improved User Experiences
For end-users, RAG translates to more reliable and informative interactions with AI systems. Whether it’s getting advice on complex topics or staying updated with the latest news, RAG ensures that users receive the most relevant and current information available.
Continuous Learning and Adaptation Without Re-training
One of the most promising aspects of RAG is its potential for continuous learning and adaptation. As external data sources evolve, RAG systems can dynamically update their knowledge base, maintaining their relevance and accuracy over time.
6. Outro
By integrating retrieval with generation, RAG unlocks new possibilities, making LLMs more powerful, versatile, and effective in solving complex real-world problems.
With RAG, LLMs can access and utilize real-time information, providing better accuracy and relevance in their responses. To get LLMs to “integrate” custom data when generating responses you do not need to spend millions on pre-training and fine-tuning. For a large fraction of the end-users, setting up a RAG pipeline can go a long way in generating relevant results.
Further Reading
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks: https://arxiv.org/abs/2005.11401
Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models: https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
Continue reading more:



Consider subscribing to get it straight into your mailbox:
I would also recommend anyone looking for more info the following paper: https://arxiv.org/abs/2312.10997