
"Attention, Please!": A Visual Guide To The Attention Mechanism [Transformers Series]
Develop an intuition behind Attention: what it does and why it took over machine learning + LLMs

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
Consider sharing this with someone who wants to know more about machine learning.

What do LLMs (like ChatGPT4 [2], Gemini [3, 4], Claude [5], LLAMA [6]), DeepMind’s protein folding AlphaFold [7] and multi-modal model CLIP [9] have in common?
They all use transformer architecture with attention mechanisms at their core to solve problems across domains.
In the Transformer series, we go over the ingredients that have made Transformers a universal recipe for machine learning.
First up, we take a visual dive to understand the attention mechanism:
Why transformers and attention took over.
Developing a visual intuition behind Attention.
Understanding what Attention does with an example.
How it can be vectorized for efficiency.
1. Transformers Have Taken Over
In 2017, with Attention is All You Need [1], the Transformer architecture burst onto the machine learning scene, forever changing the game. The Transformer, since then, has become a popular architecture choice for a variety of tasks. It is capable of capturing long-range dependencies in data making it a powerful tool not only for NLP but also for computer vision, audio, and protein folding.

LLMs [2, 3, 4, 5, 6], machine translation [1], question-answering, protein folding [7], image classification (ViT) [8], segmentation [10], and multi-modal models [11] such as CLIP [9] all use the transformer architecture.

2. Why “Attention Is All You Need”?
Before Transformers, recurrent models (for sequences) and convolutional neural networks (for images) were the default architecture picks. With the introduction of self-attention in Transformers, some of the bottlenecks were resolved:
Computational complexity: Self-attention is faster than recurrent layers for shorter sequences (typical in NLP) due to fewer sequential operations. The complexity is lowered to O(N^2 * D) from recurrent layers with O(N * D^2) where D is the dimensionality and N is the length of the input sequence.
Parallelization: Self-attention allows for more parallel processing compared to recurrent layers. RNNs have a limitation in that they are sequential. To compute a state, all past states need to be computed. This prevents scaling in terms of model and dataset size. Vectorized attention (using matrix multiplication) is designed to maximize parallelization.
Long-range dependencies: Learning long-range dependencies is key for tasks that deal with sequences [1]. Self-attention connects all positions in the sequence with a constant number of operations, making learning long-range dependencies easier than recurrent and convolutional layers.
But what truly sets Transformers apart is the clever use of the attention mechanism. This mechanism is the secret sauce that allows the model to understand the relationships between different parts of the data, something crucial for tasks like understanding the context of a sentence or recognizing objects within an image.
3. Intuition Behind Attention: Dictionary 2.0
Here is what the attention equation looks like. Let’s not get intimidated! In this section break down each element of the equation to understand what it is trying to do.
Attention is a “learnable”, “fuzzy” [12] version of a key-value store.
A key-value store is also known as a hashtable or dictionary in some programming languages.

A dictionary takes a key and maps it to a value. Generally, each key is mapped to a single value. For example, in a dictionary that contains the country capital as the key-value pair, each country would map to a single capital city. For the query “Italy”, the matching key in the dictionary is “Italy” with the value “Rome”.

Instead of matching the query to exactly one key in the dictionary, attention deals with it in a non-binary manner. In the attention mechanism, the query can match more than one key. For each key, a score quantifies how well the query matches with this key.
Here, the query, keys, and values are D-dimensional feature vectors. These can be outputs of previous layers or the learned embeddings of the encoded tokens. The matrices contain learnable parameters that are optimized during training. This makes this a versatile dictionary that is fuzzy as well as end-to-end trainable.
Why softmax? The scores are normalized using softmax to be weights that sum to 1 and each weight is between 0 and 1, like a well-behaved probability distribution.
4. What does Attention do?
Attention is applied to the input sequence and generates weights for what is of importance to each query. These weights then help “pick” the relevant information and pass it on to the next layer in the model.
Let's consider the sentence: “The quick brown fox jumps over the lazy dog.”
Here's an example of how attention might generate different scores for the word “jumps”:
Query Vector: The model generates a vector representation for the word “jumps”. This vector acts as the query.
Key and Value Vectors: Each word in the sentence also has a corresponding key and value vector.
Dot Product and Scaling: The query vector is compared with each key vector using a dot product. This score is then divided by the square root of the key dimension for stability.
Softmax: The resulting scores are passed through a softmax function, transforming them into attention weights between 0 and 1. These weights represent the relative importance of each word in the sentence to the word “jumps”.

As you can see, the attention mechanism assigns the highest score to “fox” as it is the subject performing the action. Other words like “quick” and “over” receive moderate scores due to their semantic connection to the act of jumping. Words like “the” and “dog” have lower scores as their relevance to “jumps” is less direct.
This is a simplified example, and the actual attention scores can vary depending on the specific model and training data. However, it demonstrates how the attention mechanism dynamically assigns weights based on the relevance of different words to a specific query within the sentence.

5. Making Attention More Efficient: Vectorized Operation
Once, we have the building block, the attention can be re-written using linear algebra. Instead of dealing with each vector one by one, all the vectors (queries, keys, and values) can be stacked together to form matrices: Q, K, and V.
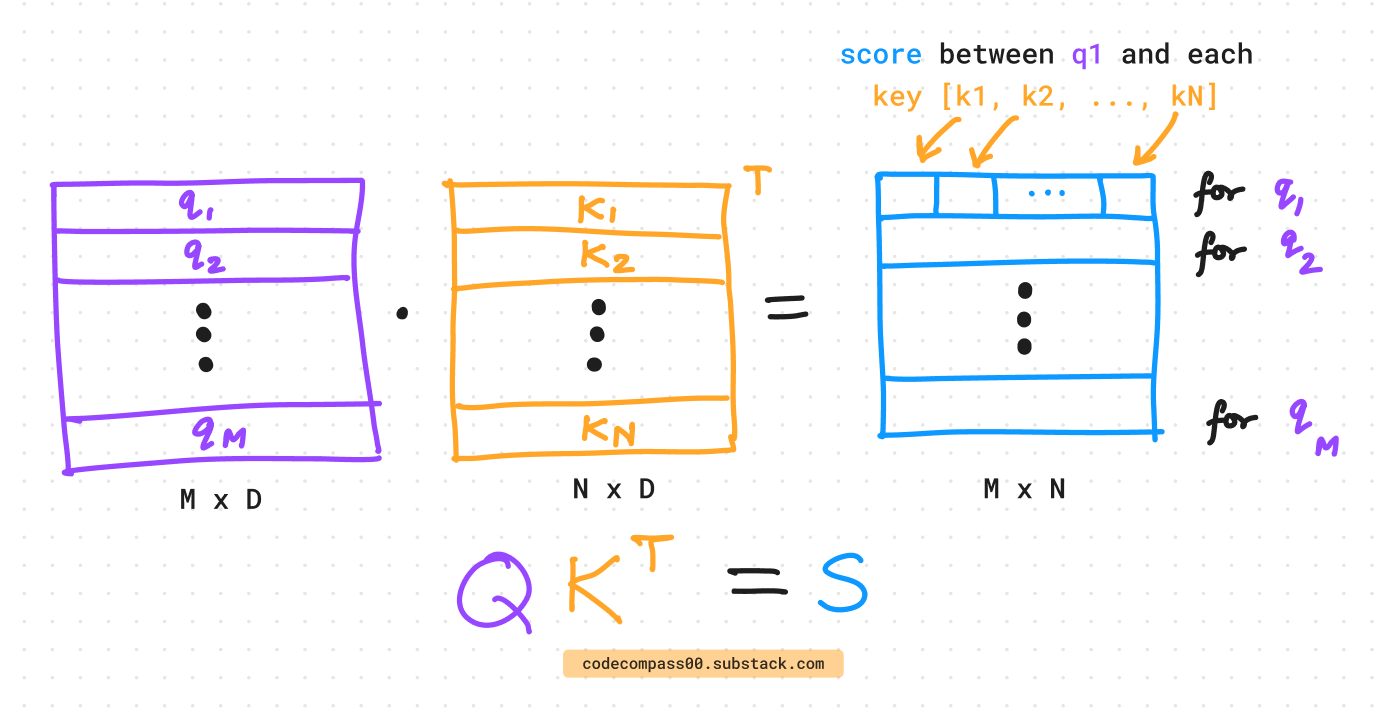
First, we take the queries Q and keys K to compute the similarity score S. This score S tells for a given query, which keys are “interesting”. It is easier to think of the operations when we write out the dimensions of each of these matrices.

This is then used to weigh the values and generate the output as seen above. Finally, we can put all of this together to write it as a single equation.
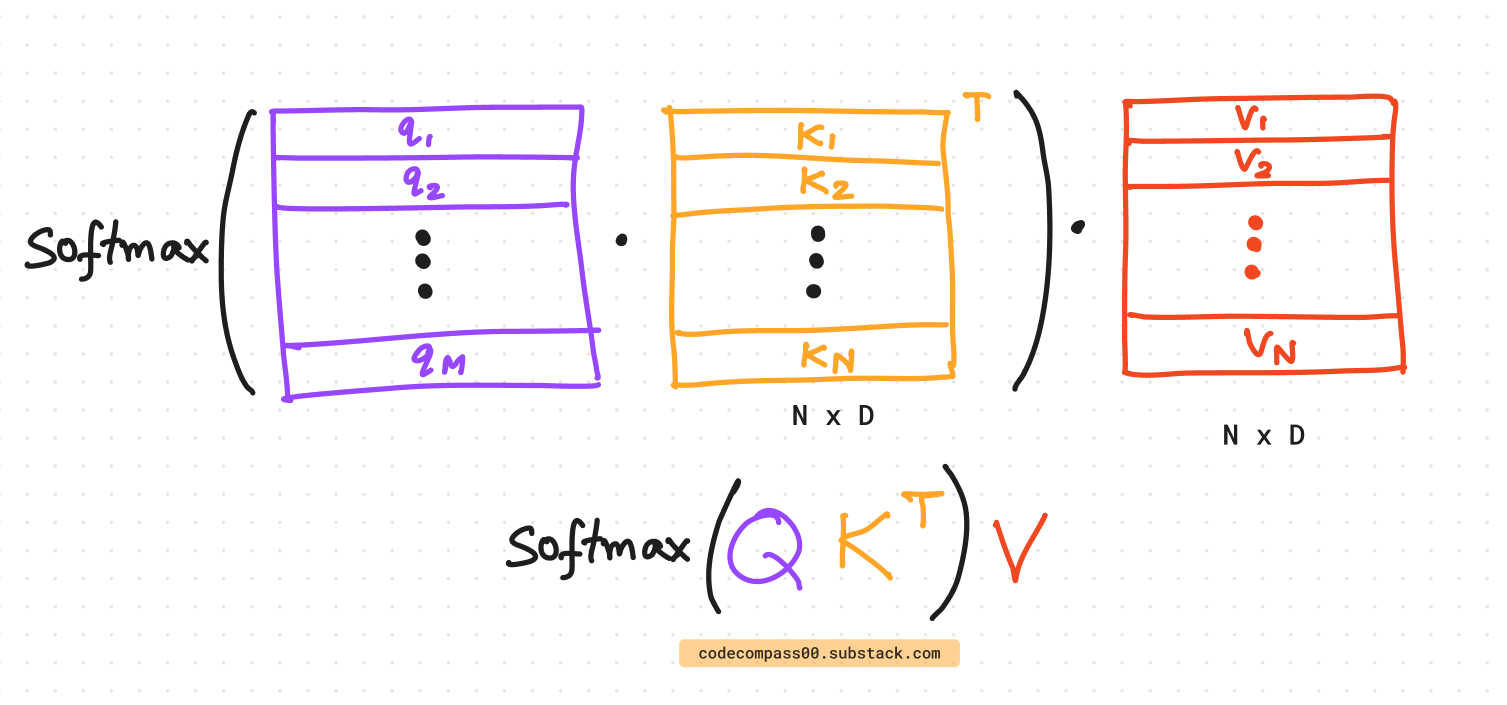
This vectorization is a more efficient implementation of the same attention mechanism.
In the above, we omit the scaling by `1/sqrt(d_k)` for simplicity. It is needed to scale down large dot product values and prevent smaller gradients from the softmax function. [1]
Here is a snippet in Python using Pytorch that computes attention:
import torch
import torch.nn.functional as F
def attention(Q, K, V):
"""
Performs attention mechanism on three input matrices.
B = batch size,
M = number of queries,
N = number of key-value pairs,
D = feature dimension.
Args:
Q: Query matrix with shape (B, M, D).
K: Key matrix with shape (B, N, D).
V: Value matrix with shape (B, N, D).
Returns:
output: Weighted sum of the values based on
attention scores, with shape (B, M, D).
attention_weights: Attention weights with
shape (B, M, N).
"""
# Calculate attention scores with scaling by sqrt(d_k)
d_k = Q.size(-1)
scaler = torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / scaler
# Input: Q (B, M, D), K (B, N, D)
# Output: attention_scores (B, M, N)
# Apply softmax to get attention weights
attention_weights = F.softmax(attention_scores, dim=-1)
# Input: attention_scores (B, M, N)
# Output: attention_weights (B, M, N)
# Multiply weights with values and sum
output = torch.matmul(attention_weights, V)
# Input: attention_weights (B, M, N), V (B, N, D)
# Output: output (B, M, D)
return output, attention_weights6. Is “Attention All You Need”?
Indeed, attention is one of the crucial ingredients that made transformers and everything that uses them (yes, I am looking at you LLMs) a massive breakthrough in the world of machine learning. However, there are more supporting mechanisms than just attention that make transformers so good. In this series, we go over the building blocks that have made transformers so universal. Stay tuned for the next part of the Transformer series.
Until then,
"Autobots, transform and roll out!" - Optimus Prime
The next part in the series is here:
![Transformers and the Power of Positional Encoding [Transformers Series]](https://substackcdn.com/image/fetch/$s_!RubY!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc88ffcf7-5fa5-4405-bd70-048cce0002cf_1669x777.png)
Consider subscribing to get it straight into your mailbox:
Continue reading more:




References
[1] Attention Is All You Need: https://arxiv.org/abs/1706.03762
[2] GPT-4 Technical Report: https://arxiv.org/abs/2303.08774
[3] Gemini: A Family of Highly Capable Multimodal Models: https://arxiv.org/abs/2312.11805
[4] Gemini 1.5: https://arxiv.org/abs/2403.05530
[5] Claude 3: https://www.anthropic.com/news/claude-3-family
[6] LLAMA: https://arxiv.org/abs/2302.13971
[7] AlphaFold: https://www.nature.com/articles/s41586-021-03819-2
[8] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929
[9] CLIP: Connecting text and images: https://openai.com/index/clip
[10] SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
[12] Fuzzy Logic
Consider sharing this newsletter with somebody who wants to learn about machine learning: