
How OpenAI Uses LLMs to Explain Neurons Inside LLMs
Explaining Neuron Behavior at Scale + Neuron Viewer

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
Consider sharing this with someone who wants to know more about machine learning.

New here and don’t know where to begin?
Read the Getting Started page to find your way around The Code Compass.
0. Interpreting Neurons
You may have heard of the grandmother neuron (sometimes also called the “Jennifer Aniston neuron”) [1] which is a cell that fires when exposed to the concept of grandma. So when the brain sees grandma or hears her, this neuron fires. This term was coined by Jerry Letvin in 1969. And decades later, we saw how this came about to be the case in neural networks, specifically, CNNs [2, 3].


![[Jupyter Notebook] Build Your Own Open-source RAG Using LangChain, LLAMA 3 and Chroma](https://substackcdn.com/image/fetch/$s_!s1v9!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F87ac01f1-0169-4922-8b67-cbcaaba60fae_1117x574.png)
Like CNNs, this phenomenon has been observed in their language counterparts, i.e., language models that begin to tie certain concepts to certain neurons after seeing data. This could be achieved by training a model using supervised learning i.e. having X, y pairs of data that are fed to the model and let the parameters gradient-descent their way into a not-so-optimal-but-good-enough local minima.
With the coming of transformers and LLMs where scaling laws are clearly visible; the architecture is not the bottleneck anymore but it is the data. Research labs and companies small and large have gone all out to get more and more data that can be used to pre-train such models.
Would like to read other related pieces?
Here you can read more about the Transformers series and LLMs series.
This makes large models like ChatGPT [8], Claude [11], LLAMA [12], Gemini [9, 10], and the rest extremely powerful and more capable than ever however with little insight into what is going on inside those thousands and thousands of matrices that make such models.
Now these LLMs are orders of magnitude larger than CNNs. Interpreting neurons for CNNs could be done manually but this clearly won’t scale for models the size of today’s LLMs.
1. Explaining Neuron Behavior At Scale
So, OpenAI took this and said, let’s automate the interpretability and scale it to LLMs and friends. They also open-sourced the code on GitHub [13].
“This work is part of the third pillar of our approach to alignment research: we want to automate the alignment research work itself. A promising aspect of this approach is that it scales with the pace of AI development. As future models become increasingly intelligent and helpful as assistants, we will find better explanations.” - OpenAI
So how do they automate sifting through trillions of weights?
The answer is in the question itself: they use an LLM to interpret and find grandmother neurons in other LLMs, how slick is that?

OpenAI uses multiple models to perform neuron interpretation as scale:
A subject model that is to be interpreted.
An explainer model that interprets the behavior of the subject model.
A simulator model that predicts based on the explanation.
To interpret the behavior of a single neuron, the algorithm used by OpenAI is as follows with the following parts.
I recommend looking at the interactive demo and the pre-computed neuron explanations that OpenAI has made available. See references for links. [5, 6, 7]

2. Explain The Neuron’s Behavior
The explainer model is given a prompt with a few-shot examples. The explainer model is tasked with coming up with an explanation given a list of tokens and their corresponding activation values e.g.
Here is a neuron N that activates in the following manner for different tokens:
{“cat”: 8, “dog”: 7, “pencil”: 0, “rabbit”: 9, “snow”: 0, …}.
The explainer model is given a few examples such as the one above with their correct interpretation and then has to hypothesize the subject neuron’s behavior.
For such an example the explainer would predict that neuron N is a neuron that activates when it sees a token that reminds it of animals i.e. an animal neuron.

What are these activation scores?
The activation is the real-number output of the neuron for a given token.
The activations can be negative or positive.
Negative activation values are clamped to 0.
The remaining positive activations are scaled to a value between 0 and 10.
Further, they are discretized to integer values only.
You can read our dedicated series to learn more about Transformers and LLMs.
!["Attention, Please!": A Visual Guide To The Attention Mechanism [Transformers Series]](https://substackcdn.com/image/fetch/$s_!mFbk!,w_1300,h_650,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F375dc525-fa19-4e6f-81f2-68820bfd36a1_1903x856.png)
Sparse Activations → Modified Prompt
If a certain neuron only activated for less than 20% of the tokens, then some extra information is appended to the prompt.
This contains the list of tokens and their corresponding activation but without the token-value pairs that have a value of 0.
OpenAI says this helps the model focus on the relevant tokens i.e. the few tokens that have non-zero activation values.
3. Simulate The Neuron's Behavior
Once the explainer model has generated an explanation for the neuron's behavior, OpenAI uses the next step to cross-validate the correctness of a hypothesis. Given a neuron and the hypothesis generated by the explainer, the simulator model is asked to predict how this neuron would activate for each token in a given sequence, based on that explanation.

The simulator model is prompted to output an integer from 0-10 for each token in the subject model's vocabulary. The expected value of these outputs is then calculated to produce a simulated neuron activation on a [0, 10] scale.
OpenAI describes two methods for simulation:
One-at-a-time method: This involves predicting the activation for each token individually which is slow.
All-at-once method: This parallelizes predictions across all tokens by using a clever prompting technique. This method is faster and found to be as accurate as the one-at-a-time approach.

4. Score The Explanation
To evaluate the quality of the explanation, OpenAI compares the simulated neuron behavior against the actual neuron behavior. This is done by comparing the simulated activation values to the real activation values across multiple text excerpts.

The main scoring method used is correlation scoring, which calculates the correlation coefficient (ρ) between the true and simulated activations.
A score of 1 indicates perfect simulation, while a score around 0 suggests the explanation is unrelated to the neuron's behavior.
OpenAI also validated their scoring method against:
Ablation scoring: This involves replacing the real neuron with the simulated neuron and measuring the change in network behavior.
Human scoring: Human evaluators were asked to rate and rank explanations based on how well they capture activation patterns.
5. Design Decisions
Text excerpts: OpenAI uses 64-token contiguous subsequences from the subject model's pre-training dataset for both generating and simulating explanations.
Explanation generation: 5 “top-activating” text excerpts are used, which contain extremely large activation values. This approach yielded the best explanation scores.
Scoring: Two types of scoring are reported:
Random-only: Uses 5 uniformly random text excerpts
Top-and-random: Uses a mix of 5 top-activating and 5 random text excerpts
Models: GPT-2 is typically used as the subject model, while GPT-4 serves as both the explainer and simulator models.
This approach allows OpenAI to generate, simulate, and evaluate explanations for individual neurons in large language models, providing insights into their behavior and functionality.
6. Improving Explanations
The methodology approached human-level scores, however, the explanations could be improved by making some adjustments such as:
Iterating with counter-examples: Ask the explainer model to come up with counter-examples and use them to revise the initially proposed explanation for the neuron.
Using a larger explainer model: That was coming.
Using a larger simulator model: No kidding, Sherlock!
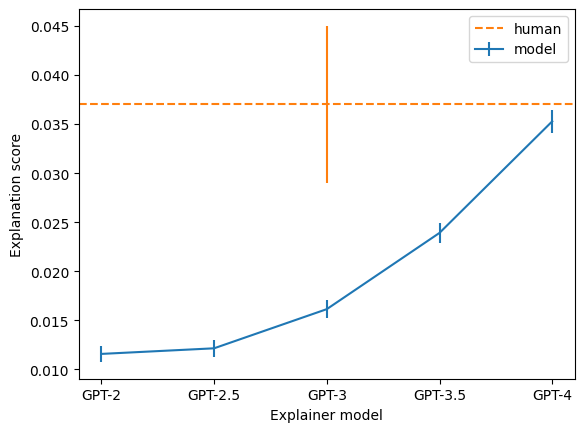
7. Interesting Findings: Pattern-break Neurons & Others
Some neurons fired when they saw a break in the pattern.

Another neuron activated highly in the presence of a simile, and another one that fires after the occurrence of a typo! [4]
More such neurons can be examined here [5].

8. Outro
As a machine learning practitioner, the key outlook is the potential for automated interpretability methods to revolutionize our understanding of large language models. The future promises more sophisticated explainer models that can generate and test complex hypotheses about neural networks, potentially leading to breakthroughs in understanding model behavior. The prospect of visualizing patterns across millions of neurons and applying these techniques to model auditing and alignment issues is particularly exciting. This research direction could bridge the gap between model complexity and interpretability, paving the way for more transparent and reliable AI systems.
Further Reading
[1] Grandmother cell
[2] Activation Atlas
[4] Typo neuron
[8] GPT-4 Technical Report: https://arxiv.org/abs/2303.08774
[9] Gemini: A Family of Highly Capable Multimodal Models: https://arxiv.org/abs/2312.11805
[10] Gemini 1.5: https://arxiv.org/abs/2403.05530
[11] Claude 3: https://www.anthropic.com/news/claude-3-family
[12] LLAMA: https://arxiv.org/abs/2302.13971
[13] GitHub Repo
Continue reading more:




Consider subscribing to get it straight into your mailbox: