
Dropout: A Simple Solution to a Complex Problem
Learn about dropout, its variants and how to apply them in your next project

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
To read more on this topic see the references section at the bottom. Consider sharing this post with someone who wants to know more about machine learning.

0. Introduction
Overfitting [10] is a major obstacle in training deep neural networks. It occurs when the network “memorizes” the training data too well, leading to poor performance on unseen examples. Dropout, a simple and elegant technique introduced in 2012, offers a powerful solution to this problem.

We delve into the technical details of (the original) Dropout and its variants, explore their successful applications, and provide practical advice for incorporating it into your own neural network architectures.
1. Dropout: Tackling Overfitting Head-On
First Introduced
Dropout was introduced by Hinton et al. in their paper “Improving neural networks by preventing co-adaptation of feature detectors” [2, 5] in 2012. It is one of the de-facto regularizers [9] in the neural network world.
Usefulness
Dropout prevents overfitting by randomly deactivating neurons during training, encouraging the network to learn robust features from different subsets of neurons during training. This is done on the activations and not the weights. It is commonly used after fully connected layers.

Technical Details
Dropout introduces randomness during training by probabilistically dropping out neurons, effectively creating an ensemble of thinned networks.
During each training iteration, a fraction of the input units (neurons) is set to zero with a specified probability, typically between 0.2 and 0.5. This stochastic process encourages the network to learn robust representations by preventing reliance on specific neurons and promoting feature generalization.
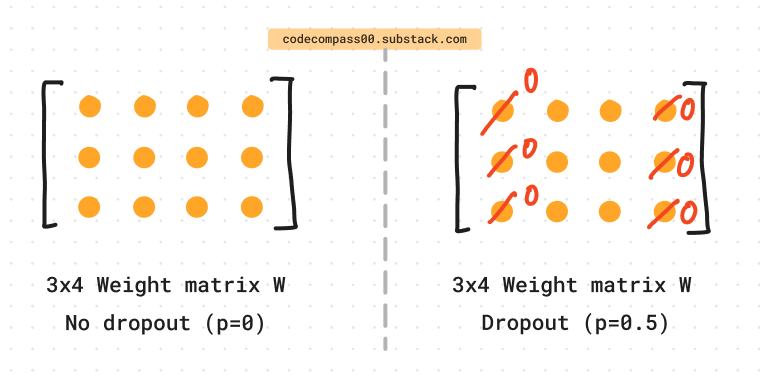
During training, to compensate for the deactivated neurons, the remaining activations are scaled up by a factor of 1 / (1 - p), ensuring the expected average activation remains unchanged.
Let’s assume that we set p=0.1 during training. This means when we do many batches of forward pass, each neuron will be masked 10% of the time i.e. on average only 90% of the signal is passed on to the next layer. During training, the output is scaled by 1/(1-0.1) = 1/0.9, so we can offset the fact that only 90% or 0.9 of the signal is passed on to the next layer.
During deployment, dropout behaves as an identity function i.e. the output is the input.
Difference from Other Dropout Variants
Sets individual activations to zero and not the weight itself. It is applicable to any layer type.
Effective for regularization [9] and preventing overfitting in various neural network architectures. This technique has been instrumental in the success of numerous deep learning architectures, including the architecture that won the 2012 ImageNet competition, a breakthrough1 in computer vision (Krizhevsky et al., 2012 [4]).

Practical Advice
Start without any dropout and set up the training pipeline. Once set, when the training loss is lower than the validation loss it signals overfitting. That is a good sign to use dropout.
Begin with a dropout rate between 0.2 and 0.5. Monitor model performance closely during training to detect any signs of underfitting or overfitting, and adjust dropout rates accordingly.
Be cautious when applying dropout to small datasets or networks with fewer parameters, as aggressive dropout rates may lead to worse generalization.
Continue reading more:



!["Attention, Please!": A Visual Guide To The Attention Mechanism [Transformers Series]](https://substackcdn.com/image/fetch/$s_!mFbk!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F375dc525-fa19-4e6f-81f2-68820bfd36a1_1903x856.png)
![Transformers and the Power of Positional Encoding [Transformers Series]](https://substackcdn.com/image/fetch/$s_!RubY!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fc88ffcf7-5fa5-4405-bd70-048cce0002cf_1669x777.png)
