

Transformers and the Power of Positional Encoding [Transformers Series]
Transformers and the Power of Positional Encoding [Transformers Series]
How Transformers Find Order In Data

Get a list of personally curated and freely accessible ML, NLP, and computer vision resources for FREE on newsletter sign-up.
Consider sharing this with someone who wants to know more about machine learning.

Not sure where to begin? You can read the last post in the Transformers Series below:
!["Attention, Please!": A Visual Guide To The Attention Mechanism [Transformers Series]](https://substackcdn.com/image/fetch/w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F375dc525-fa19-4e6f-81f2-68820bfd36a1_1903x856.png)
The Rise of The Transformer
Before delving into positional encoding, let's briefly touch upon the rise of Transformers. In 2017, the introduction of the Transformer architecture in the seminal paper “Attention is All You Need” revolutionized the field of natural language processing (NLP) and eventually the whole of machine learning.
Unlike traditional sequential models such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs), Transformers leveraged the power of attention mechanisms to capture long-range dependencies efficiently. This breakthrough paved the way for Transformer-based models like BERT, GPT, and T5, which achieved remarkable success across NLP tasks.
Introduction
At the heart of the Transformer architecture lies the self-attention mechanism, enabling the model to weigh the relevance of different tokens in the input sequence dynamically.

However, unlike sequential models such as RNNs that inherently possess positional information through the order of tokens, Transformers treat input sequences as unordered sets. This lack of positional understanding could pose a significant challenge, particularly for tasks where the order of elements is crucial, such as language understanding.
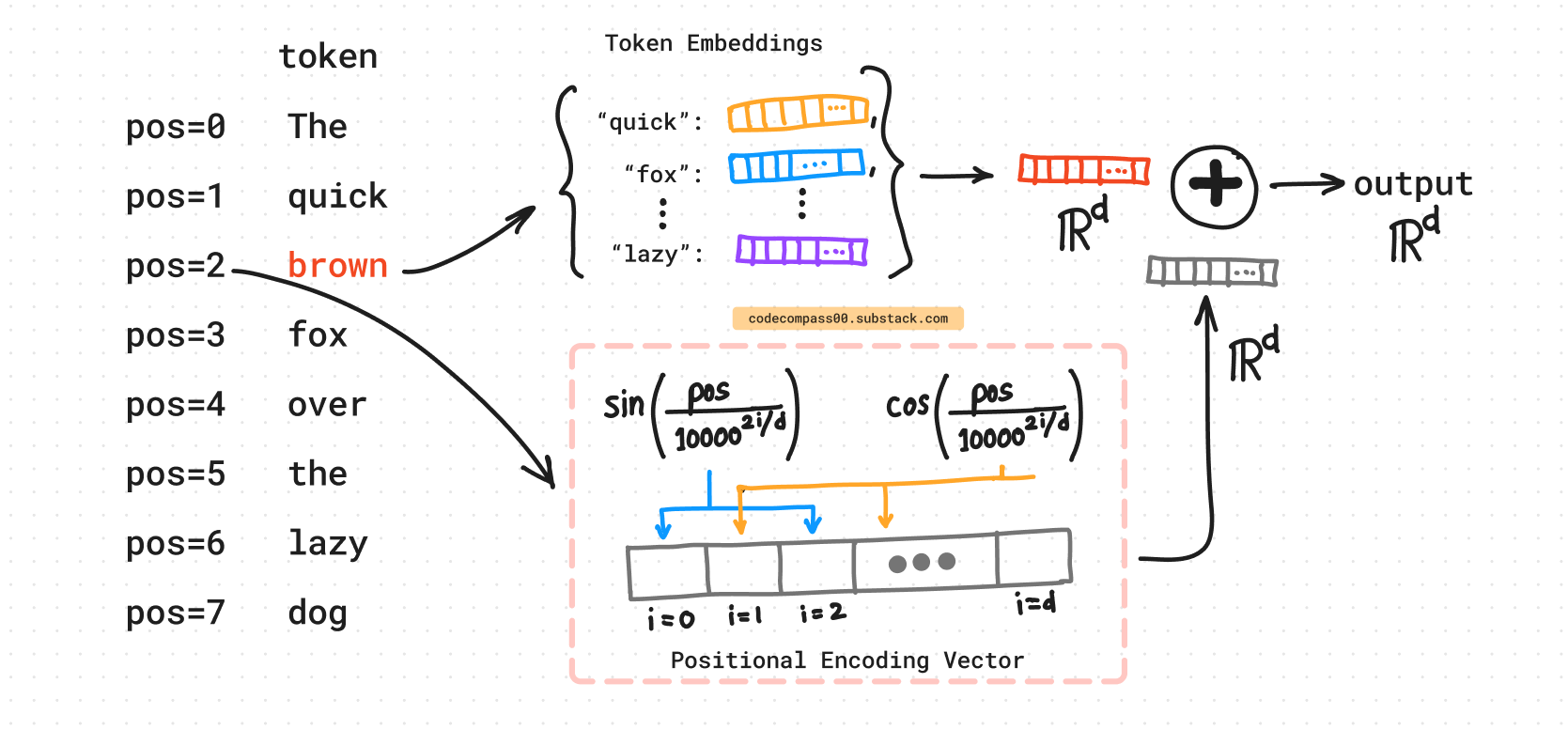
This is where positional encoding comes into play. Positional encoding is a mechanism used to inject positional information into the input embeddings, enabling the Transformer to discern the sequential order of tokens. By encoding each token's position within the sequence, positional encoding equips the model with the necessary spatial awareness to process sequences effectively.
In this article, we discuss the importance of positional encoding in Transformers.
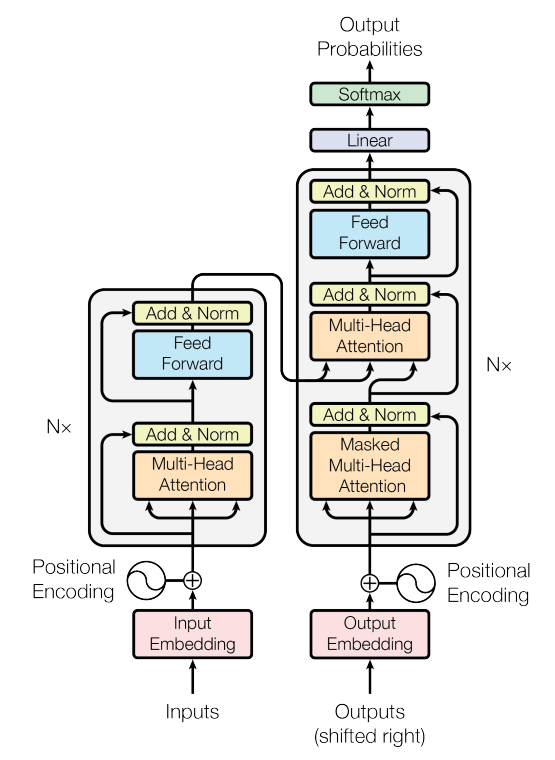
1. What is Positional Encoding?
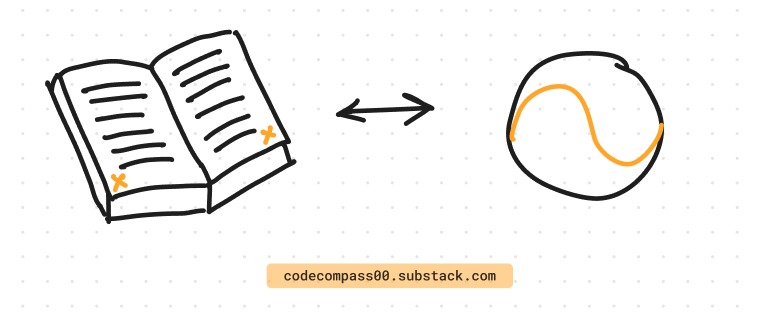
1.1 An Analogy: Reading a Book
To understand positional encoding intuitively, let's consider a simple analogy. Imagine you're reading a book without page numbers or chapter headings. While you can still comprehend the individual words and sentences, you might struggle to grasp the overarching structure and narrative flow. Positional encoding in some sense is equivalent to adding page numbers and chapter headings to the book, providing contextual cues that aid in comprehension.
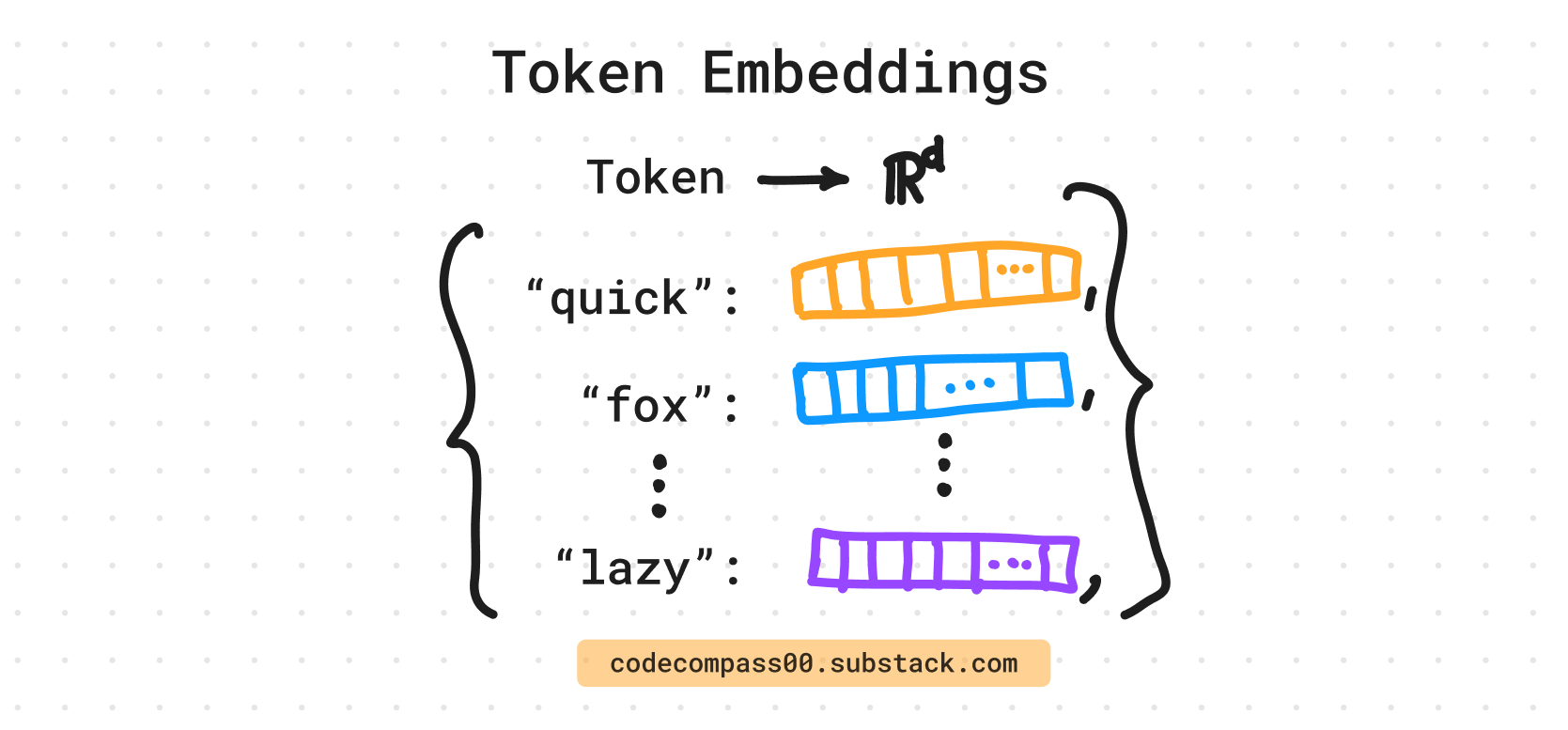
**Illustration:** A diagram showing tokens and their corresponding positional encoding, which are then combined to produce the final input.
1.2 Why is Positional Encoding Important?
The order of elements in a sequence is often crucial for understanding the overall meaning. The self-attention mechanism does not come with a built-in ordering. Any token (word in the sentence) can attend to any other word (more on that later). Without positional encoding, the transformer would struggle to understand the sequential nature of tokens (words).
2. The Mechanics of Positional Encoding
At its core, positional encoding involves adding sinusoidal functions of different frequencies and phases to the input embeddings. These sinusoidal functions encode positional information by generating unique patterns for each position within the sequence. By incorporating these patterns into the input embeddings, the Transformer can differentiate between tokens based on their positions.
2.1 The Formula
The positional encoding formula combines sine and cosine functions to generate unique positional vectors. The formula for the positional encoding for a given position pos and embedding dimension i is:
Positional encoding when i is even:
Positional encoding when i is odd:
where:
PE(pos, i): Represents the positional encoding for position “pos” and dimension “i”.
pos: Denotes the position of the word in the sequence (starting from 0).
i: Represents the dimension of the word embedding (index within the embedding vector).
d: Indicates the dimensionality of the word embedding (total number of elements in the embedding vector).
10000 - A scaling factor (hyperparameter) chosen based on experimentation ([1] used 10,000).
Key points to note:
This formula defines the positional encoding for even and odd dimensions of the embedding vector separately.
The scaling factor (10000) controls how quickly the positional encoding values change with position. A larger value leads to smoother encoding but might not capture very short-range dependencies.
The positional encodings have the same dimensionality d as the feature vectors in the Q, K, and V matrices.
The positional embeddings for position pos and pos+1 should be very similar as they are very close positions.
This is a pre-defined (non-trainable) form of positional encoding. There are also methods where the model learns positional encodings during training. The paper [1] notes that both learned and fixed embeddings had similar empirical performance.
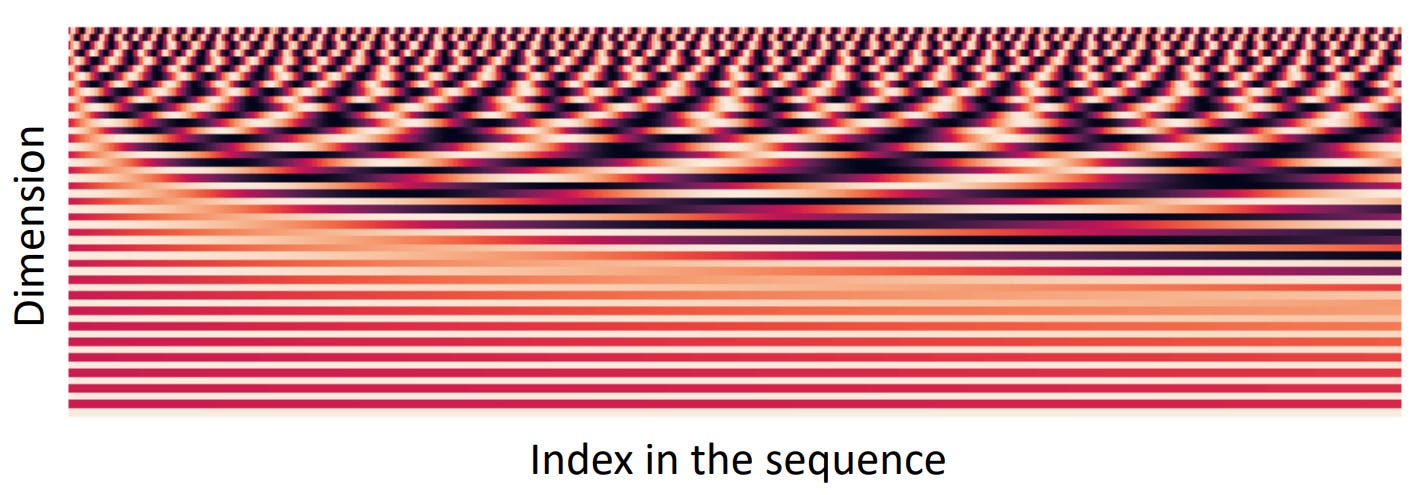
One can imagine these positional encoding vectors as writing the position index in binary. You will notice a similarity between the graph above and the binary representations below. For dimension d=0 (d=0 is the top row in the graph), the “bit” flips every time, if you go to d=1, the bit flips less often, and when d>1, the bit flips at an even lower rate. What the binary representation is doing in a discrete form (just made of 1s and 0s), the positional encodings are doing the same but in a continuous form (each element of the vector is a float).

2.2 Design Choice: Why Sine and Cosine?
Periodicity: Sine and cosine functions are periodic, meaning their values repeat over a certain interval. This characteristic is crucial for capturing the relative position of words in a sequence.
Generalizable: Regardless of the sequence length (a short sentence or a long document), the positional encoding for a specific word position relative to another word position will remain consistent due to the repeating nature of these functions. Any input length can be encoded without having to modify the functions.
Bounded Values: Sine and cosine functions have outputs between -1 and 1. This keeps the positional encoding values within a manageable range, preventing them from exploding or vanishing during calculations within the Transformer architecture.
Adjacent positions have similar PE vectors: The choice of these functions ensures that similar positions have similar encodings, which aligns with how sequences are often structured i.e. PE(pos) and PE(pos+1) are very similar.
2.3 Integrating Positional Encoding By Addition
In practice, positional encoding is added to token embeddings before feeding them into the transformer model. This combined representation equips the model with both token-specific features and positional information, enabling it to contextualize tokens accurately within the sequence.
2.4 Alternative Positional Encoding By Concatenation
The word (token) embeddings live in a d dimensional space. One could concatenate the positional encoding which is also d dimensional to obtain a final vector that has 2d elements. However, since the embeddings are learned, if the transformer finds the added positional encoding useful, it can learn the word embeddings in the latter dimensions of the d dimensional, leaving the first few dimensions to contain purely the positional encoding information that comes from the addition. This way, the model can make use of the same information efficiently without expanding the dimensionality of the embeddings.

3. Positional Encodings Variants
3.1 Learned Positional Embeddings
Instead of using fixed sine and cosine functions, positional information can also be learned [6]. Learned positional embeddings assign a unique trainable vector to each position. This approach gives the model flexibility to learn the optimal positional representation for each specific task.
3.2 Rotary Positional Encodings
Rotary Positional Encodings [5] (RoPE) rotate pairs of dimensions in the embedding space to encode positions. This method is effective for capturing longer context lengths.
Outro
Positional encoding is a simple yet powerful concept that allows transformers to process sequential data effectively. By leveraging sine and cosine functions, positional encoding provides unique and informative positional information to each token. This technique plays a crucial role in many transformer-based applications, from NLP to image processing. Understanding and utilizing positional encoding is key to unlocking the full potential of transformers.
There are more supporting mechanisms than just attention and positional encoding that make transformers what they are. In this series, we go over the building blocks that have made transformers so universal. Stay tuned for the next part of the Transformer series or read the previous piece of the series on attention.
Until then,
"Autobots, transform and roll out!" - Optimus Prime
Consider subscribing to get it straight into your mailbox:
Continue reading more:



References
[1] Attention Is All You Need: https://arxiv.org/abs/1706.03762
[2] Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929)
[3] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: https://arxiv.org/abs/1810.04805
[4] ViT: An Image is Worth 16x16 Words: https://arxiv.org/abs/2010.11929
[5] Rotary Positional Embeddings: https://arxiv.org/abs/2104.09864
[6] Convolutional Sequence to Sequence Learning: https://arxiv.org/abs/1705.03122
Consider sharing this newsletter with somebody who wants to learn about machine learning: